5bei.cn大模型教程网
5bei.cn大模型教程网
Stable Diffusion支持多人排队使用
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...

大家好,我是画画的小强 在之前文章中我已经介绍了AI绘画Stable Diffusion 的各种入门使用,从今天开始正式进入SD ControlNet系列文章介绍,感谢大家的持续支持和鼓励,不管如何,要想掌握一门技术,最重要的事是:多练习!...
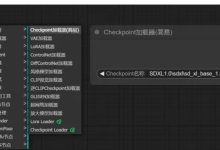
前言 ComfyUI作为一款基于Stable Diffusion的节点式操作界面,为用户提供了一个更加灵活和高效的文生图(文本生成图像)创作环境。本篇博客将详细介绍如何使用ComfyUI进行文生图操作,无论你是初学者还是有一定基础的用户,都...

Transformer模型相对复杂,下面我将提供一个简化版的Transformer模型的Python代码示例,使用PyTorch库实现。这个示例将包括模型的基本结构,如编码器和解码器,自注意力机制,位置编码,以及前馈网络。 请注意,这个示例...

🏆 作者简介,愚公搬代码 🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,...

使用sd做艺术字时,发现字体对结果有很大的影响。具体的配置参数写在了最后面,配置主要参考了博主天一寨主的博客:Stable diffusion做创意字体设计,泰裤辣(附教程) – 知乎。 如果使用的字体直线多、棱角分明,生成的图...

Whisper 是 OpenAI 研发的一个通用的语音识别模型,可以把语音转为文本。它在大量多样化的音频数据集上进行训练,同时还是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。 一、使用场景 语音 => 文字 是一个非常...
1. 模型的微调 1.1 大模型LLaMa下载 先下载一个完整版本的LLaMa模型,官网的或别人下载微调过的中文版本的。 1.2 指令微调 执行run_clm_sft_with_peft 1.3 合并LORA 大模型的原始参数和微调后的参数...

大家好,我是风雨无阻。 本期内容: Embedding是什么? Embedding有什么作用? Embedding如何下载安装? 如何使用Embedding? 大家还记得 AI 绘画Stable Diffusion 研究(七) 一文读懂 S...

核心 和diffusion相比,使用了latent(隐式空间)做diffusion,这样速度更快!!! SD模型的主体结构如下图所示,主要包括三个模型: autoencoder:encoder将图像压缩到latent空间,而decoder将...