 5bei.cn大模型教程网
5bei.cn大模型教程网一、摘要
本文主要讲述了在线性回归模型下如何使用梯度下降法。首先,通过生成模拟数据来测试梯度下降法的效果,数据包括一维的x向量和由线性公式及噪声生成的y值。然后,通过编写函数计算损失函数J的值,并处理可能的溢出问题。接着,介绍了梯度下降法的关键部分,即编写函数计算损失函数对θ的导数,使用空数组存储结果,并具体展示了如何计算第一个元素的导数,为后续多维情况的计算奠定基础。
二、线性回归算法损失函数公式推导
-
损失函数 J,参数 theta
公式:
J
=
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
J = sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
J=∑i=1m(y(i)−y^(i))2
导数可以代表方向,对应J增大的方向
∇
J
=
(
∂
J
∂
θ
0
,
∂
J
∂
θ
1
,
.
.
.
,
∂
J
∂
θ
n
)
nabla J = (frac{partial J}{partialtheta_{0}},frac{partial J}{partialtheta_{1}},…,frac{partial J}{partialtheta_{n}})
∇J=(∂θ0∂J,∂θ1∂J,…,∂θn∂J)
θ
=
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
theta = (theta_{0},theta_{1},…,theta_{n})
θ=(θ0,θ1,…,θn)
解释:
- 损失函数
J
=
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
J = sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
J=∑i=1m(y(i)−y^(i))2用于衡量线性回归模型预测值y
^
(
i
)
hat{y}^{(i)}
y^(i)与真实值y
(
i
)
y^{(i)}
y(i)之间的误差,m
m
m是样本数量。我们的目标是最小化这个损失函数。 - “导数可以代表方向,对应J增大的方向”:在函数中,导数表示函数的变化率,在损失函数的场景下,它指向损失函数值增大的方向。
-
∇
J
=
(
∂
J
∂
θ
0
,
∂
J
∂
θ
1
,
.
.
.
,
∂
J
∂
θ
n
)
nabla J = (frac{partial J}{partialtheta_{0}},frac{partial J}{partialtheta_{1}},…,frac{partial J}{partialtheta_{n}})
∇J=(∂θ0∂J,∂θ1∂J,…,∂θn∂J)是损失函数J
J
J关于参数θ
0
,
θ
1
,
.
.
.
,
θ
n
theta_{0}, theta_{1}, … , theta_{n}
θ0,θ1,…,θn的梯度,它是一个向量,每个元素是J
J
J对相应参数的偏导数。 -
−
η
∇
J
-etanabla J
−η∇J表示梯度的反方向,其中η
eta
η是学习率。梯度下降法就是沿着梯度的反方向(即−
η
∇
J
-etanabla J
−η∇J )更新模型参数θ
=
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
theta = (theta_{0},theta_{1},…,theta_{n})
θ=(θ0,θ1,…,θn),使得损失函数J
J
J的值不断减小,逐步找到损失函数的最小值。
- 损失函数
-
将损失函数公式变换,如下所示:
公式:
损失函数目标:使∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
∑i=1m(y(i)−y^(i))2尽可能小
y
^
(
i
)
=
θ
0
+
θ
1
X
1
(
i
)
+
θ
2
X
2
(
i
)
+
.
.
.
+
θ
n
X
n
(
i
)
hat{y}^{(i)} = theta_{0} + theta_{1}X_{1}^{(i)}+ theta_{2}X_{2}^{(i)}+ … + theta_{n}X_{n}^{(i)}
y^(i)=θ0+θ1X1(i)+θ2X2(i)+…+θnXn(i)
损失函数变换:使∑
i
=
1
m
(
y
(
i
)
−
θ
0
−
θ
1
X
1
(
i
)
−
θ
2
X
2
(
i
)
−
.
.
.
−
θ
n
X
n
(
i
)
)
2
sum_{i = 1}^{m}(y^{(i)} – theta_{0} – theta_{1}X_{1}^{(i)} – theta_{2}X_{2}^{(i)} – … – theta_{n}X_{n}^{(i)})^2
∑i=1m(y(i)−θ0−θ1X1(i)−θ2X2(i)−…−θnXn(i))2尽可能小。
损失函数公式解释:- 在线性回归中,我们的目的是找到一个线性模型来拟合数据。这里的
y
^
(
i
)
hat{y}^{(i)}
y^(i)表示模型预测值,它是一个关于特征变量X
1
(
i
)
,
X
2
(
i
)
,
.
.
.
,
X
n
(
i
)
X_{1}^{(i)}, X_{2}^{(i)}, … , X_{n}^{(i)}
X1(i),X2(i),…,Xn(i)的线性组合,θ
0
,
θ
1
,
.
.
.
,
θ
n
theta_{0}, theta_{1}, … , theta_{n}
θ0,θ1,…,θn是模型的参数。 - 第一个“目标”中的公式
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
∑i=1m(y(i)−y^(i))2是均方误差(MSE)损失函数,y
(
i
)
y^{(i)}
y(i)是真实值,y
^
(
i
)
hat{y}^{(i)}
y^(i)是预测值,m
m
m是样本数量。通过梯度下降法,就是要不断调整参数θ
0
,
θ
1
,
.
.
.
,
θ
n
theta_{0}, theta_{1}, … , theta_{n}
θ0,θ1,…,θn,使得这个损失函数的值尽可能小,从而让模型的预测值更接近真实值 。 - 第二个“目标”是将
y
^
(
i
)
hat{y}^{(i)}
y^(i)的表达式代入第一个损失函数后的形式,本质上与第一个目标一致,都是为了通过优化参数来最小化预测值和真实值之间的误差。
- 在线性回归中,我们的目的是找到一个线性模型来拟合数据。这里的
-
将损失函数公式继续变换,最终如下所示:

目标:使
1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
frac{1}{m}sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
m1∑i=1m(y(i)−y^(i))2尽可能小。这个公式其实就是MSE均方误差:
J
(
θ
)
=
M
S
E
(
y
,
y
^
)
J(theta) = MSE(y,hat{y})
J(θ)=MSE(y,y^)
有时取:J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
J(theta)=frac{1}{2m}sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
J(θ)=2m1∑i=1m(y(i)−y^(i))2
对J
(
θ
)
J(theta)
J(θ)求偏导数得到损失函数的梯度:
∇
J
(
θ
)
=
(
∂
J
/
∂
θ
0
∂
J
/
∂
θ
1
∂
J
/
∂
θ
2
⋯
∂
J
/
∂
θ
n
)
=
2
m
⋅
(
∑
i
=
1
m
(
X
b
(
i
)
θ
−
y
(
i
)
)
∑
i
=
1
m
(
X
b
(
i
)
θ
−
y
(
i
)
)
⋅
X
1
(
i
)
∑
i
=
1
m
(
X
b
(
i
)
θ
−
y
(
i
)
)
⋅
X
2
(
i
)
⋯
∑
i
=
1
m
(
X
b
(
i
)
θ
−
y
(
i
)
)
⋅
X
n
(
i
)
)
nabla J(theta) =begin{pmatrix} partial J/partialtheta_{0} \ partial J/partialtheta_{1} \ partial J/partialtheta_{2} \ cdots \ partial J/partialtheta_{n} end{pmatrix} =frac{2}{m} cdot begin{pmatrix} sum_{i = 1}^{m}(X_{b}^{(i)}theta – y^{(i)}) \ sum_{i = 1}^{m}(X_{b}^{(i)}theta – y^{(i)}) cdot X_{1}^{(i)}\ sum_{i = 1}^{m}(X_{b}^{(i)}theta – y^{(i)}) cdot X_{2}^{(i)}\ cdots \ sum_{i = 1}^{m}(X_{b}^{(i)}theta – y^{(i)}) cdot X_{n}^{(i)} end{pmatrix}
∇J(θ)=
∂J/∂θ0∂J/∂θ1∂J/∂θ2⋯∂J/∂θn
=m2⋅
∑i=1m(Xb(i)θ−y(i))∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋯∑i=1m(Xb(i)θ−y(i))⋅Xn(i)
解释:
-
目标函数:在线性回归中,核心目标是让模型预测值
y
^
(
i
)
hat{y}^{(i)}
y^(i)和真实值y
(
i
)
y^{(i)}
y(i)之间的误差尽可能小。1
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
frac{1}{m}sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
m1∑i=1m(y(i)−y^(i))2 是均方误差(MSE)的表达式,m
m
m代表样本数量,通过最小化该式来优化模型。J
(
θ
)
=
M
S
E
(
y
,
y
^
)
J(theta) = MSE(y,hat{y})
J(θ)=MSE(y,y^) 是将均方误差定义为关于参数θ
theta
θ的损失函数。有时也会使用1
2
m
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
frac{1}{2m}sum_{i = 1}^{m}(y^{(i)} – hat{y}^{(i)})^2
2m1∑i=1m(y(i)−y^(i))2 作为损失函数,这是为了在后续求导计算时消除系数,简化计算过程。 -
梯度计算:
∇
J
(
θ
)
nabla J(theta)
∇J(θ) 表示损失函数J
(
θ
)
J(theta)
J(θ) 关于参数θ
theta
θ的梯度,是一个向量,每个元素是J
(
θ
)
J(theta)
J(θ) 对相应参数θ
j
theta_{j}
θj(j
j
j从0到n
n
n)的偏导数。公式右边展示了具体的偏导数计算方式,其中X
b
(
i
)
X_{b}^{(i)}
Xb(i) 是包含截距项的第i
i
i个样本的特征向量 ,这些偏导数的计算结果用于梯度下降算法中更新参数θ
theta
θ,沿着梯度的反方向调整参数,逐步找到损失函数的最小值。
-
目标函数:在线性回归中,核心目标是让模型预测值
三、应用梯度下降法训练线性回归算法模型
-
生成测试数据
- 生成一维向量x模拟100个样本,每个样本只有一个特征。
- 使用线性方式生成y,通过3乘以x再加上4,并添加噪音。
- 噪音采用正态分布,均值为零,方差为一。
- 代码如下:
import numpy as np import matplotlib.pyplot as plt # 设置随机数种子为 666,这使得每次运行代码时生成的随机数序列是相同的,方便结果的复现。 np.random.seed(666) # 使用numpy的random.random函数生成 100 个取值在 0 到 1 之间的随机数,然后乘以 2,得到一个包含 100 个随机数的一维数组x,作为自变量。 x = 2 * np.random.random(size=100) # 根据线性关系y = 3x + 4生成因变量y,并加入了服从标准正态分布的随机噪声(通过np.random.normal生成 100 个随机数),模拟真实世界中的数据分布情况。 y = x * 3. + 4. + np.random.normal(size=100) # 将x变成二维矩阵形式 X = x.reshape(-1, 1)
-
编写损失函数
def J(theta, x_b, y): try: return np.sum((y - x_b.dot(theta))**2) / len(x_b) except: return float('inf')解释:
计算线性回归中的损失函数(均方误差MSE)。具体解释如下:-
def J(theta, x_b, y)::定义了一个名为J的函数,接受三个参数,theta代表模型的参数向量,x_b是包含特征变量的矩阵(可能已经添加了截距项),y是真实值向量。 -
np.sum((y - x_b.dot(theta))**2) / len(x_b):x_b.dot(theta)表示矩阵x_b与参数向量theta的点积,即计算模型的预测值;(y - x_b.dot(theta))计算真实值和预测值的差值;(y - x_b.dot(theta))**2对差值进行平方;np.sum((y - x_b.dot(theta))**2)对所有样本的平方误差求和;最后np.sum((y - x_b.dot(theta))**2) / len(x_b)将总误差除以样本数量len(x_b),得到均方误差,作为损失函数的返回值。这里np应该是导入的numpy库,用于数值计算。 -
except块:如果在计算过程中出现异常(比如数据格式错误等情况),函数将返回正无穷float('inf')。
-
-
编写损失函数的梯度
def dJ(theta, x_b, y): res = np.empty(len(theta)) res[0] = np.sum(x_b.dot(theta) - y) for i in range(1, len(theta)): res[i] = (x_b[:,i].dot((x_b.dot(theta) - y)) * 2 / len(x_b)) return res计算线性回归中损失函数(均方误差)关于参数
theta的梯度。具体解释如下:-
def dJ(theta, x_b, y)::定义了一个名为dJ的函数,接受三个参数,theta代表模型的参数向量,x_b是包含特征变量的矩阵(可能已经添加了截距项),y是真实值向量。 -
res = np.empty(len(theta)):使用numpy库中的empty函数创建一个和theta长度相同的空数组res,用于存储梯度的各个分量。 -
res[0] = np.sum(x_b.dot(theta) - y):单独计算参数theta的第一个分量(通常对应截距项)的梯度。x_b.dot(theta)计算模型的预测值,x_b.dot(theta) - y是预测值和真实值的差值,np.sum(x_b.dot(theta) - y)对这些差值求和,得到关于第一个参数的梯度值并存入res[0]。 -
for循环部分:-
for i in range(1, len(theta))::遍历参数theta中除第一个元素外的其他元素。 -
res[i] = (x_b[:,i].dot((x_b.dot(theta) - y)) * 2 / len(x_b)):对于每个参数分量theta[i],x_b[:,i]取出矩阵x_b的第i列特征,(x_b.dot(theta) - y)依旧是预测值与真实值的差值,x_b[:,i].dot((x_b.dot(theta) - y))计算特征列与误差的点积,乘以2(这是均方误差求导后的系数)并除以样本数量len(x_b),得到关于theta[i]的梯度值,存入res[i]。
-
-
return res:最后将计算得到的整个梯度向量res返回。
-
-
实现梯度下降法
def gradient_descent(x_b, y, initial_theta, eta, n_iters = 1e4, epsilon=1e-8): theta = initial_theta i_iter = 0 while i_iter n_iters: gradient = dJ(theta, x_b, y) last_theta = theta # 迭代更新theta参数 theta = theta - eta * gradient if(abs(J(theta, x_b, y) - J(last_theta, x_b, y)) epsilon): break i_iter += 1 return theta这是一段使用Python编写的梯度下降算法函数,用于在给定数据和初始参数的情况下,通过迭代更新参数来最小化线性回归的损失函数。具体解释如下:
-
def gradient_descent(x_b, y, initial_theta, eta, n_iters = 1e4, epsilon):定义了一个名为gradient_descent的函数,接受6个参数。x_b是包含特征变量的矩阵(可能已添加截距项),y是真实值向量,initial_theta是参数的初始值,eta是学习率,n_iters是最大迭代次数(默认值为10000),epsilon是用于判断是否收敛的阈值。 -
theta = initial_theta:将初始参数值赋给theta,后续在迭代过程中theta会不断更新。 -
i_iter = 0:初始化迭代次数计数器为0。 -
while i_iter :开始一个循环,只要当前迭代次数小于最大迭代次数,就会继续执行。-
gradient = dJ(theta, x_b, y):调用dJ函数(之前定义的用于计算梯度的函数),计算当前参数theta下的梯度。 -
last_theta = theta:保存当前的参数值,用于后续比较损失函数的变化。 -
theta = theta - eta * gradient:根据梯度下降的公式更新参数theta,沿着梯度的反方向移动,移动的步长由学习率eta和梯度gradient决定。 -
if(abs(J(theta, x_b, y) - J(last_theta, x_b, y)) :计算更新前后损失函数(通过J函数计算)的差值绝对值,如果该值小于设定的阈值epsilon,说明损失函数变化很小,认为算法已经收敛,跳出循环。 -
i_iter += 1:每次循环结束后,迭代次数计数器加1。
-
-
return:函数结尾的return语句,当前函数返回最终优化后的参数theta。
-
-
准备和调用梯度下降法训练
x_b = np.hstack([np.ones((len(x), 1)), x.reshape(-1,1)]) initial_theta = np.zeros(x_b.shape[1]) eta = 0.01 theta = gradient_descent(x_b, y, initial_theta, eta) # 打印theta值 theta这段Python代码是线性回归中使用梯度下降法的一部分前置准备和调用操作,具体如下:
-
x_b = np.hstack([np.ones((len(x), 1)), x.reshape(-1,1)]):-
np.ones((len(x), 1))使用numpy库的ones函数创建一个形状为(len(x), 1)的二维数组,其中每个元素都是1,这里len(x)表示样本数量,这一步是为了添加截距项对应的特征列。 -
x.reshape(-1,1)将特征变量数组x转换为一个二维列向量,-1表示根据原数组的元素数量自动推断这一维的长度。 -
np.hstack函数将上述两个数组在水平方向上进行拼接,得到包含截距项特征和原特征的新数组x_b,用于后续线性回归计算。
-
-
initial_theta = np.zeros(x_b.shape[1]):使用numpy库的zeros函数创建一个形状为x_b.shape[1]的一维数组,其中每个元素都是0。这里x_b.shape[1]表示特征的数量(包括截距项对应的特征),这个数组作为线性回归模型参数theta的初始值。 -
eta = 0.01:定义学习率eta,值为0.01,在梯度下降算法中用于控制每次参数更新的步长。 -
theta = gradient_descent(x_b, y, initial_theta, eta):调用之前定义的gradient_descent函数,传入包含特征的矩阵x_b、真实值向量y、初始参数initial_theta和学习率eta,通过梯度下降算法对参数进行优化,并将最终得到的最优参数赋值给theta。
-
-
实验过程
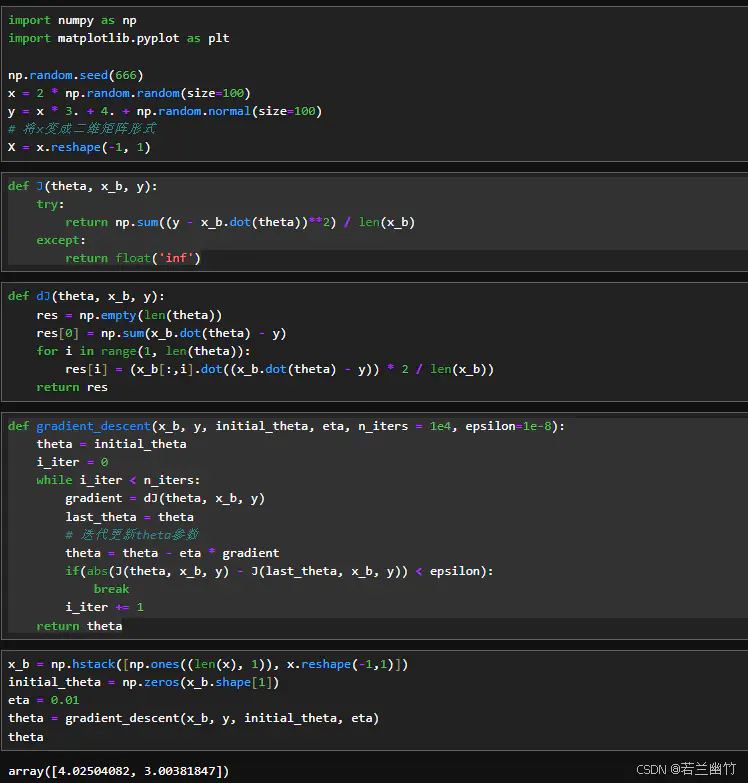
四、梯度下降法求得结果的意义
- 代码中通过梯度下降法最终得到的结果
theta = array([4.02504082, 3.00381847]),分别对应线性回归模型y = theta_0 + theta_1x中的参数θ
0
theta_0
θ0和θ
1
theta_1
θ1 。 -
θ
0
theta_0
θ0(约为4.02504082)是截距项,意味着当自变量x
x
x为0时,因变量y
y
y的估计值约为4.02504082 。 -
θ
1
theta_1
θ1(约为3.00381847)是斜率,表明自变量x
x
x每增加1个单位,因变量y
y
y大约会增加3.00381847个单位。 - 原始数据是按照
y
=
3
x
+
4
+
ϵ
y = 3x + 4 + epsilon
y=3x+4+ϵ(ϵ
epsilon
ϵ是噪声)生成的,而通过梯度下降法拟合得到的参数接近真实的参数值(截距接近4,斜率接近3 ),说明梯度下降法在该线性回归模型中有效地找到了能较好拟合数据的参数,使得模型可以根据自变量x
x
x来对因变量y
y
y进行相对准确的预测。
文章来源于互联网:【机器学习】应用梯度下降法训练线性回归算法模型












