 5bei.cn大模型教程网
5bei.cn大模型教程网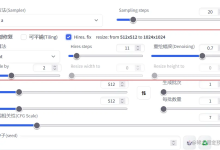
Stable Diffusion支持多人排队使用
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...

Whisper 是 OpenAI 研发的一个通用的语音识别模型,可以把语音转为文本。它在大量多样化的音频数据集上进行训练,同时还是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。 一、使用场景 语音 => 文字 是一个非常...

前言 AnimateDiff 是一个实用框架,可以对文本生成图像模型进行动画处理,无需进行特定模型调整,即可为大多数现有的个性化文本转图像模型提供动画化能力。而Animatediff 已更新至 2.0 版本和3.0两个版本,相较于 1.0 ...
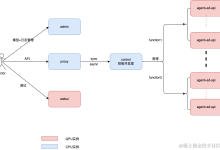
作者:王佳、江昱、筱姜 Stable Diffusion 模型,已经成为 AI 行业从传统深度学习时代走向 AIGC 时代的标志性里程碑。越来越多的开发者借助 stable-diffusion-webui(以下简称 SDWebUI)能力进行...
提前总结 显卡要好,显存要高 素材像素要好,数量越多越好 素材不必要的元素越少越好,太多就扣像留白底 要好好的打标签,影响最终效果 硬件要求 建议N卡且显卡显存至少8G,显存越高越好(即价格越贵越好); 4G需要调整参数,而且速度较慢,不推...

使用openai-whisper实现语音转文字 1 安装依赖 1.1 Windows下安装ffmpeg FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及...

“选用适当的模型,随随便便出个图,都要比打上一堆提示词的效果要好。” 事实如此,高质量的模型,能够成倍提升出图质量。目前 CivitAI(俗称 C 站, https://civitai.com/ )是业内比较成熟的一个 Stable Dif...

Stable Diffusion(稳定扩散)是一种生成式大模型,它在AI领域中标志着一个新的里程碑,为我们揭示了未来将会是AIGC的时代。传统的深度学习模型逐渐向AIGC过渡,这也意味着我们需要学习更多关于AIGC的内容。 如果你和我一样是...

前言 老铁留言推荐无用师,那么今天它来了~ 今天试玩的是无用师大佬称作的终结版,正如大佬所言,都SD3了,再加上Pony系、Kolors 、混元等众多大模型系列。但老徐觉得在1.5的大模型中很多依然是很能打。虽然在艺术性,镜头感上1.5已经...

一、基础模型下载 本文的背景是微调一个基于Llama3的中文版模型Llama3-8B-Chinese-Chat,用于中文指定领域的问答下游任务 1、HuggingFace官网直接下载 官网地址:https://huggingface.co/...
 【AI绘画】个人电脑部署免费AI绘画软件——Stable Diffusion webui启动器2024-08-14
【AI绘画】个人电脑部署免费AI绘画软件——Stable Diffusion webui启动器2024-08-14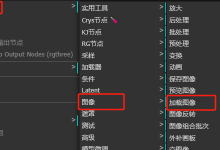 AI绘画,一步一步徒手搭建ComfyUI工作流,教你编辑和修改工作流,ComfyUI入门教程2025-01-12
AI绘画,一步一步徒手搭建ComfyUI工作流,教你编辑和修改工作流,ComfyUI入门教程2025-01-12 【Stable Diffusion】最新换脸模型:IP-Adapter Face ID Plus V2 WebUI 效果超赞!2025-01-20
【Stable Diffusion】最新换脸模型:IP-Adapter Face ID Plus V2 WebUI 效果超赞!2025-01-20 Stable Diffusion本地化部署超详细教程(手动+自动+整合包三种方式)2025-02-06
Stable Diffusion本地化部署超详细教程(手动+自动+整合包三种方式)2025-02-06 Stable Diffusion & ComfyUI(一)2025-01-29
Stable Diffusion & ComfyUI(一)2025-01-29