 5bei.cn大模型教程网
5bei.cn大模型教程网
全面对标GPT-4o!不锁区、支持手机、免费使用,Moshi来啦!
7月4日凌晨,法国知名开源AI研究实验室Kyutai在官网发布了,具备看、听、说多模态大模型——Moshi。 Moshi功能与OpenAI在5月14日展示的最新模型GPT-4o差不多,可以听取人的语音提问后进行实时推理回答内容。但GPT-4...
7月4日凌晨,法国知名开源AI研究实验室Kyutai在官网发布了,具备看、听、说多模态大模型——Moshi。 Moshi功能与OpenAI在5月14日展示的最新模型GPT-4o差不多,可以听取人的语音提问后进行实时推理回答内容。但GPT-4...

和GhostReivew一个思路,还是从比较好的图片或者是civitai上找一些热门的prompt,从小红书上也找到了不少的prompt,lexica.art上也有不少,主要是为了电商场景的一些测评: 小红书、civitai、Lexica、...

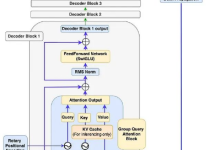
原理 Vanilla Transformer 与 LLaMa 的区别 主流的大语言模型都采用了Transformer架构,它是一个基于多层Self-attention的神经网络模型。 原始的Transformer由编码器(Encoder)和...

接上篇文章,这期使用文心一言图像识别API,对本地图片以及在线视频图片进行内容理解。 该请求用于图像内容理解,支持输入图片和提问信息,可对输入图片进行理解,输出对图片的一句话描述,同时可针对图片内的主体/文字等进行检测与识别,支持返回图片内...

图像生成模型简介 图片生成领域来说,有四大主流生成模型:生成对抗模型(GAN)、变分自动编码器(VAE)、流模型(Flow based Model)、扩散模型(Diffusion Model)。 从2022年开始,主要爆火的图片生成模型是D...

5.5.4 Llama-2语言模型操作 编写下面的代码,功能是加载、配置 Llama-2 语言模型以及其对应的分词器,准备好模型为后续的对话生成任务做好准备。 model_name = "../input/llama-2/pytorch/...
前文 在数字化、信息化的浪潮中,人工智能(AI)技术如同一匹黑马,不断刷新着我们对科技发展的认知。其中,智能语言模型作为AI领域的一大分支,更是引领着自然语言处理(NLP)技术的革新。今天,我要为大家揭秘的,正是这一领域的新里程碑——“文心...

目录 训练的时间和效果 数据准备 数据样例 数据配置 环境搭建 模型微调训练 模型预测 运行成功的web UI LLaMA-Factory地址:https://github.com/hiyouga/LLaMA-Factory/blob/ma...

注:在做项目的时候需要调用文心一言,发现网上的版本很乱,基本都止步在官方文档的代码上,所以写了一篇博客来记录自己的尝试实现了对文心一言的循环调用和自定义询问,本篇文章不需要有任何对api的基础知识,代码全部成功运行,并引用官方文档,祝大家成...

大家好,我是花生~ 很多小伙伴都会在「优设 AI 绘画交流群」以及文章评论区中非常积极地和我探讨 Midjourney 的使用问题,我在帮助大家的同时自己也学到了不少新的技巧。今天就写一篇文章解释 3 个比较常见的疑问,希望对大家有帮助。 ...

![[AI]从零开始的llama.cpp部署与DeepSeek格式转换、量化、运行教程-5bei.cn大模型教程网](https://file.5bei.cn/2025/02/frc-f5a2712052551e672bd16d3a399e6127-220x150.png)


