 5bei.cn大模型教程网
5bei.cn大模型教程网
Stable Diffusion 训练
前言 简单介绍了Stable diffusion的训练过程。 一、主要训练方式 Stable Diffusion主要有 4 种方式:Dreambooth, LoRA, Textual Inversion, Hypernetworks 1.T...
前言 简单介绍了Stable diffusion的训练过程。 一、主要训练方式 Stable Diffusion主要有 4 种方式:Dreambooth, LoRA, Textual Inversion, Hypernetworks 1.T...

一、前言 先做个声明,下面图片都是AI工具生成,此技术不要做危害他人之事。 在AI绘画的学习过程中,有不少人希望可以用AI做个人写真,或者将AI生成的图片换成真人的脸做服装展示。训练模型也可以实现上面的需求,但是需要的图比较多,很麻烦。今天...

北大-兔展联合发起的Sora开源复现计划Open-Sora-Plan,今起可以生成最长约21秒的视频了! 生成的视频水平,如下展示。先看这个长一点的,9.2s: 下面这段人形机器人种花要短一点,是2.7s: 当然了,老规矩,这一次的所有数据...
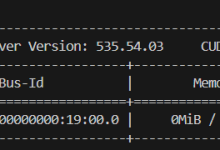
本次实验基于 Llama3-8B-Instruct 和 XTuner 团队预训练好的 Image Projector 微调自己的多模态图文理解模型 LLaVA。实验平台为InternStudio,实验所用的显存为24G。 =========...

本文介绍Stable Diffusion的快速上手,本地部署,以及更多有趣的玩法展示。 在 DALL-E 2 和 Imagen 之后,AI绘图领域又一个热乎的深度学习模型出炉——Stable Diffusion 。8月份发布的 Stable...

整理 | 王轶群 责编 | 唐小引 出品丨AI 科技大本营(ID:rgznai100) 4月19日凌晨,Meta重磅发布了全球最大开源大模型Llama 3,一夜间重新坐稳王者之位。 模型下载链接:https://llama.meta.com...

学习前言 在过年期间,OpenAI放出了SORA文生视频的预览效果,一瞬间各大媒体争相报道,又引爆了一次科技圈,可惜的是,SORA依然没选择开源。 在这个契机下,本来我也对文生视频的工作非常感兴趣,所以也研究了一些与SORA相关的技术,虽然...

(零)前言 本篇主要提到了一些热度比较高的模型,模型是每个人都可以训练和改进的,所以无穷无尽,无法真的细数。 更多不断丰富的内容参考:🔗《继续Stable-Diffusion WEBUI方方面面研究(内容索引)》 (一)基础模型(Stabl...

ChatGPT chatGPT免费网站列表:GitHub – LiLittleCat/awesome-free-chatgpt: 🆓免费的 ChatGPT 镜像网站列表,持续更新。List of free ChatGPT mir...
一波未平一波又起,不光APP被批评套壳安卓,主推的大动作模型LAM依赖OpenAI接口,现在公司也被扒皮有猫腻—— Rabbit公司本来是搞元宇宙的,原地改名转投AI?! 这家曾经主打NFT游戏的创业公司,去年转型做AI终端(即R1)。并在...



