 5bei.cn大模型教程网
5bei.cn大模型教程网Paper name
Scaling Diffusion Transformers to 16 Billion Parameters
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2407.11633
Code URL: https://github.com/feizc/DiT-MoE
TL;DR
- 2024 年昆仑万维发表的 DiT-MoE 工作。DiT-MoE 用稀疏的 MoE 层替代了 DiT 中一部分密集的前馈层,其中每个图像块的 token 都会被路由到部分专家,即 MLP 层。此外,我们的架构包含两个主要设计:共享部分专家以捕获通用知识,以及专家级平衡损失以减少不同路由专家之间的冗余。进一步将模型参数扩展到 165 亿,而只激活了 31 亿个参数,在 512×512 分辨率下达到了新的最先进 FID-50K 分数 1.80。
Introduction
背景
- Stable Diffusion 3 作为迄今为止具有竞争力的扩散模型之一,某些模型的参数量已超过 80 亿。然而,训练和服务这些模型的成本很高。这部分是因为这些深度网络通常是密集的,即每个样本都需要使用每个参数进行处理,因此扩展的计算成本很高。
- 条件计算是一种有前景的扩展技术,其目标是在应用于每个样本的参数子集时,提高模型容量,同时保持相对恒定的训练和推理成本。在自然语言处理(NLP)领域,稀疏专家混合(MoE)作为一种实用实现变得越来越流行,它通过路由机制来控制计算成本
本文方案

- 提出了 DiT-MoE,一种用于图像生成的稀疏 DiT 架构变体。DiT-MoE 用稀疏的 MoE 层替代了 DiT 中一部分密集的前馈层,其中每个图像块的 token 都会被路由到部分专家,即 MLP 层。此外,我们的架构包含两个主要设计:共享部分专家以捕获通用知识,以及专家级平衡损失以减少不同路由专家之间的冗余。
- 在 ImageNet 基准测试中进行了基于类别的图像生成评估。实验结果表明,DiT-MoE 的性能与最先进的密集模型相当,但推理时间更短。另一方面,DiT-MoE-S 可以在匹配 DiT-B 成本的同时实现更好的性能。通过额外的合成数据,我们进一步将模型参数扩展到 165 亿,而只激活了 31 亿个参数,在 512×512 分辨率下达到了新的最先进 FID-50K 分数 1.80。我们的贡献总结如下:
- 扩散 Transformer 的 MoE:我们提出了 DiT-MoE,这是一种用于图像合成的稀疏激活扩散 Transformer 模型。它结合了简单有效的设计,包括共享部分专家以捕获通用知识,以及辅助专家级平衡损失以减少路由专家之间的冗余。
- 专家路由分析:我们对不同场景下专家选择的统计数据进行了分析,发现了关于不同 MoE 层中专家选择与空间位置和去噪时间步的偏好,这些发现可以有效指导未来的网络设计和可解释性。
- 大规模模型参数:我们引入了一系列 DiT-MoE 模型,展示了这些模型可以稳定地训练,并无缝地用于高效推理。更令人鼓舞的是,我们进一步尝试证明 DiT-MoE 可以在精心选择的合成数据的支持下扩展到超过 160 亿参数。
- 性能和推理:我们表明,DiT-MoE 在 ImageNet 基准测试上的条件图像生成任务中,性能明显优于其密集模型。同时,在推理时,DiT-MoE 模型可以灵活地匹配最大密集模型的性能,而只需使用一半的计算量。最后,我们公开发布了代码和训练好的模型检查点。
Methods
MOE 回顾
- 条件计算与 MoE(专家混合模型):条件计算旨在根据输入激活神经网络的子集。专家混合模型通过将不同的模型专家分配给输入空间的各个区域来体现这一概念。专家混合层一般由 E 个专家组成,定义如下:
MoE
(
x
)
=
∑
i
=
1
E
g
(
x
)
i
e
i
(
x
)
,
text{MoE}(x) = sum_{i=1}^{E} g(x)_i e_i(x),
MoE(x)=i=1∑Eg(x)iei(x),
其中,x
∈
R
D
x in mathbb{R}^D
x∈RD 是层的输入,e
i
:
R
D
→
R
D
e_i : mathbb{R}^D rightarrow mathbb{R}^D
ei:RD→RD 表示专家i
i
i 计算的函数,g
:
R
D
→
R
E
g : mathbb{R}^D rightarrow mathbb{R}^E
g:RD→RE 是决定专家输入条件权重的路由函数。e
i
e_i
ei 和g
g
g 都由神经网络参数化。根据原始定义,这种结构仍然是一个密集网络。然而,如果g
g
g 是稀疏的,即仅分配k
≪
E
k ll E
k≪E 个非零权重,则无需计算未使用的专家。这种方法使得模型参数的数量相对于推理和训练的计算成本呈超线性扩展。
MOE-DIT
- 扩散 Transformer (DiT) 的 MoE 设计
- 与 ViT 类似,DiT 将图像作为一系列的图像块进行处理。输入图像首先被划分为等大小的图像块。这些块被线性投影为与模型隐藏维度相同的特征。在添加位置嵌入后,图像块嵌入,即图像块 token,由一系列 Transformer 块处理,这些块主要由交替的自注意力和 MLP 层组成。标准的 MLP 由两层和一个 GeLU 非线性激活函数组成:
MLP
(
x
)
=
W
2
σ
gelu
(
W
1
x
)
,
text{MLP}(x) = W_2 sigma_{text{gelu}}(W_1 x),
MLP(x)=W2σgelu(W1x),
对于 DiT-MoE,我们将其中一部分替换为 MoE 层,其中每个专家都是一个 MLP;参见图 2 以了解更多细节。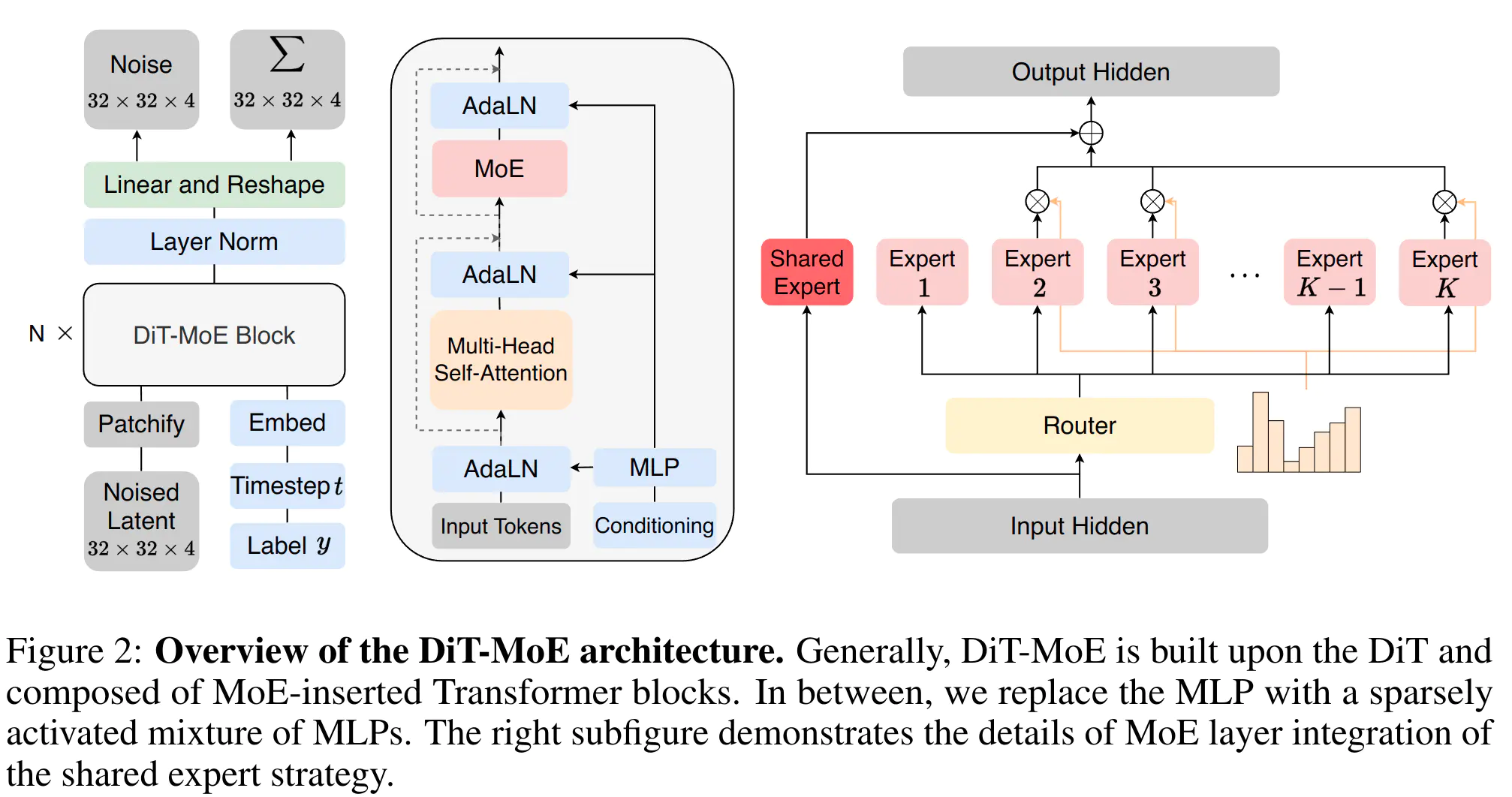
如图 2 右子图所示,我们的架构包括两个主要策略:共享专家路由和专家负载平衡损失。这两个策略均旨在优化专家专业化水平,详细介绍如下:-
共享专家路由。在传统路由策略下,分配给不同专家的 token 可能需要访问重叠的知识或信息。因此,多个专家可能在各自的参数中获取相同的知识,导致参数冗余。参考 DEEPSEEKMOE 和 DeepSpeed-MoE,我们引入了额外的
n
s
n_s
ns 个专家作为共享专家。也就是说,不论原始路由模块如何,每个图像块 token 都将被确定性地分配给这些共享专家。 -
专家级平衡损失。直接学习的路由策略通常会遇到负载不平衡的问题,从而导致显著的性能缺陷。为了解决这一问题,我们引入了专家级平衡损失,计算如下:
L
balance
=
α
∑
i
=
1
n
(
n
K
T
∑
t
=
1
T
I
(
t
,
i
)
1
T
∑
t
=
1
T
P
(
t
,
i
)
)
,
L_{text{balance}} = alpha sum_{i=1}^{n} left( frac{n}{K T} sum_{t=1}^{T} I(t, i) frac{1}{T} sum_{t=1}^{T} P(t, i) right),
Lbalance=αi=1∑n(KTnt=1∑TI(t,i)T1t=1∑TP(t,i)),
其中α
alpha
α 是专家级平衡因子,T
T
T 是图像块序列的长度,I
(
t
,
i
)
I(t, i)
I(t,i) 表示图像 tokent
t
t 选择专家i
i
i 的指示函数,P
(
t
,
i
)
P(t, i)
P(t,i) 是专家i
i
i 的 tokent
t
t 概率分布。
-
共享专家路由。在传统路由策略下,分配给不同专家的 token 可能需要访问重叠的知识或信息。因此,多个专家可能在各自的参数中获取相同的知识,导致参数冗余。参考 DEEPSEEKMOE 和 DeepSpeed-MoE,我们引入了额外的
- 与 ViT 类似,DiT 将图像作为一系列的图像块进行处理。输入图像首先被划分为等大小的图像块。这些块被线性投影为与模型隐藏维度相同的特征。在添加位置嵌入后,图像块嵌入,即图像块 token,由一系列 Transformer 块处理,这些块主要由交替的自注意力和 MLP 层组成。标准的 MLP 由两层和一个 GeLU 非线性激活函数组成:
计算量分析
-
计算分析
- 在 DiT-MoE 中,部分 MLP 被 MoE 层替代,这有助于增加模型容量,同时保持激活参数的数量,从而提高计算效率。形式上,MoE 模块每隔
e
e
e 层应用于 MLP。当使用 MoE 时,每层有n
n
n 个可能的专家,路由器在每个图像块 token 上选择前K
K
K 个专家和共享的n
s
n_s
ns 个专家。通过调整n
n
n、K
K
K 和e
e
e,此设计允许 DiT-MoE 优化各种属性。- 增加
n
n
n 会提升模型容量,但也会增加显存使用量; - 增加
K
K
K 会增加激活参数和计算需求。 - 相反,增加
e
e
e 会减少模型容量,但也会降低计算和内存需求,以及通信依赖性。
- 增加
- 表 1 中描述了 DiT-MoE 的各种配置,涵盖了从 199M 到 16.5B 的模型总规模和浮点运算分配,从而为可扩展性性能提供全面的见解。与 DiT 一致,Gflop 度量(使用了 thop Python 库)在 256×256 尺寸的图像生成中评估,图像块尺寸
p
=
2
p = 2
p=2。我们默认设置e
=
1
e = 1
e=1。模型根据其配置和图像块尺寸p
p
p 命名;例如,DiT-MoE L/2-8E2A 指的是大版本配置,p
=
2
p = 2
p=2、n
=
8
n = 8
n=8、K
=
2
K = 2
K=2。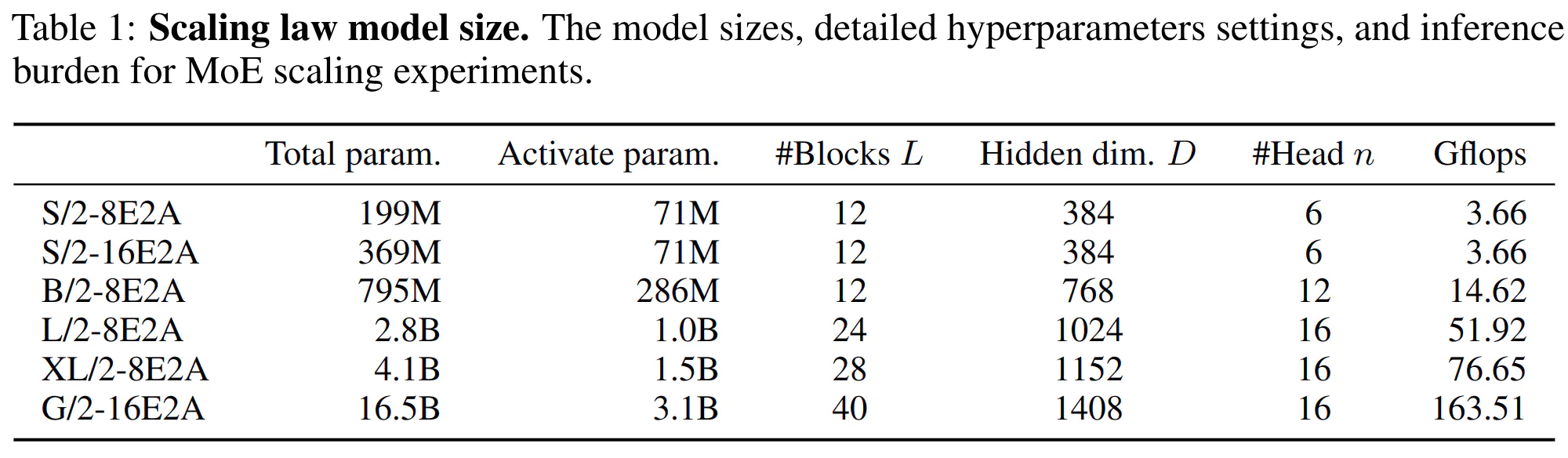
- 在 DiT-MoE 中,部分 MLP 被 MoE 层替代,这有助于增加模型容量,同时保持激活参数的数量,从而提高计算效率。形式上,MoE 模块每隔
Experiments
数据集
- 使用了 ImageNet 数据集,分辨率为 256×256 和 512×512,包含 1,281,167 张来自 1,000 个不同类别的训练图像
- 对于合成训练数据,我们使用开源的文本到图像模型,包括 SDXL 和 SD3-Medium,根据给定的标签生成了大约 500 万张不同的 512×512 图像。具体来说,我们使用提示模板“[图像类别],自然且逼真的风格。” 以不同的种子创建图像,并使用最高的 CLIP 相似度进行过滤。最后,我们构建了一个真实图像与合成图像比例为 1:5 的混合训练图像集。
实现细节
- AdamW 优化器,并且没有使用权重衰减,保持 1e-4 的恒定学习率。
- ema,衰减系数为 0.9999。所有结果均基于 EMA 模型报告。
- 在 Nvidia A100 GPU 上进行训练。
- 在不同分辨率的 ImageNet 数据集上进行训练时,采用了无分类器引导方法
- 使用来自 Stable Diffusion 中可在 huggingface 上获得的预训练变分自编码器 (VAE) 模型。VAE 编码器的下采样因子为 8。
- 我们重新训练了 DiT 中的扩散超参数,使用 tmax = 1000 的线性方差计划,范围从
1
×
1
0
−
4
1 × 10^{-4}
1×10−4 到2
×
1
0
−
2
2 × 10^{-2}
2×10−2,并对协方差进行参数化。我们将共享专家数 ns 默认为 2,将专家级平衡因子 α 默认为 0.05。
模型设计分析
消融实验
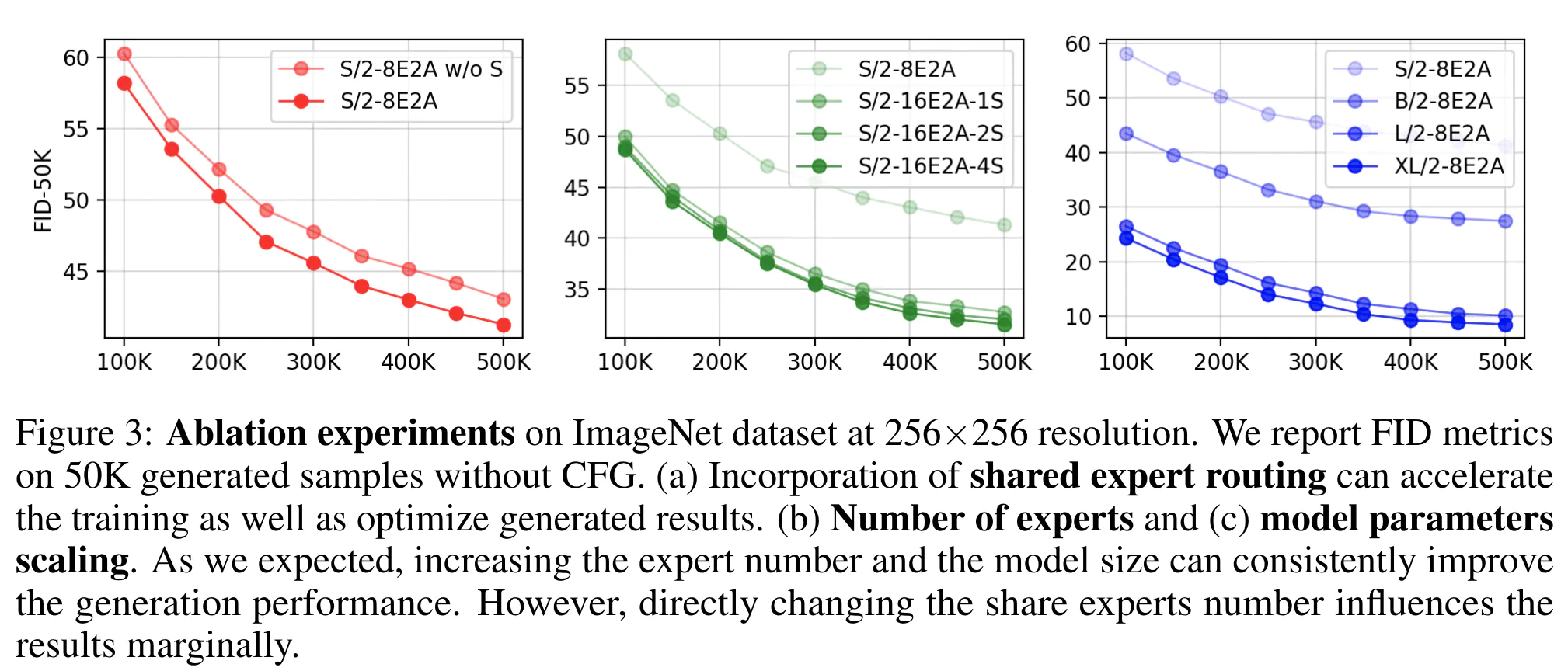
- 共享专家路由的效果
- 为了评估共享专家路由策略的影响,我们通过去除共享专家但保持与传统专家路由方法相同的激活参数数量进行消融研究,并从头开始训练模型。如图 3 (a) 所示,结果表明,与传统的专家路由相比,加入额外的共享专家在大多数步骤中增强了性能。这些发现支持了共享专家策略有助于更好地分离知识并改进 MoE 模型性能的假设。
- 最佳共享专家数量。
- 接着,我们在规模上研究了最佳共享专家数量。使用小型版本的 MoE-DiT,该模型包含 16 个专家,我们保持激活专家的数量为 2,并尝试加入 1、2 和 4 个共享专家。如图 3 (b) 所示,我们发现共享专家与路由专家的比例变化对性能没有显著影响。考虑到内存使用和性能之间的权衡,我们在扩展 DiT-MoE 时将共享专家数量标准化为 2。
- 增加专家数量的影响。
- 我们直接将专家数量从 8 增加到 16,同时保持激活参数的数量固定为 2。如图 3 (b) 所示,此调整带来了持续的生成性能提升,但 GPU 内存消耗显著增加。另一方面,图 4 中的损失曲线显示,引入 MoE 可以实现具有竞争力的性能,并有助于加速损失收敛。然而,直接增加专家数量以提高性能可能会引入更多的损失峰值。如何减少损失峰值,如峰值正则化损失,我们将在未来的工作中探讨。
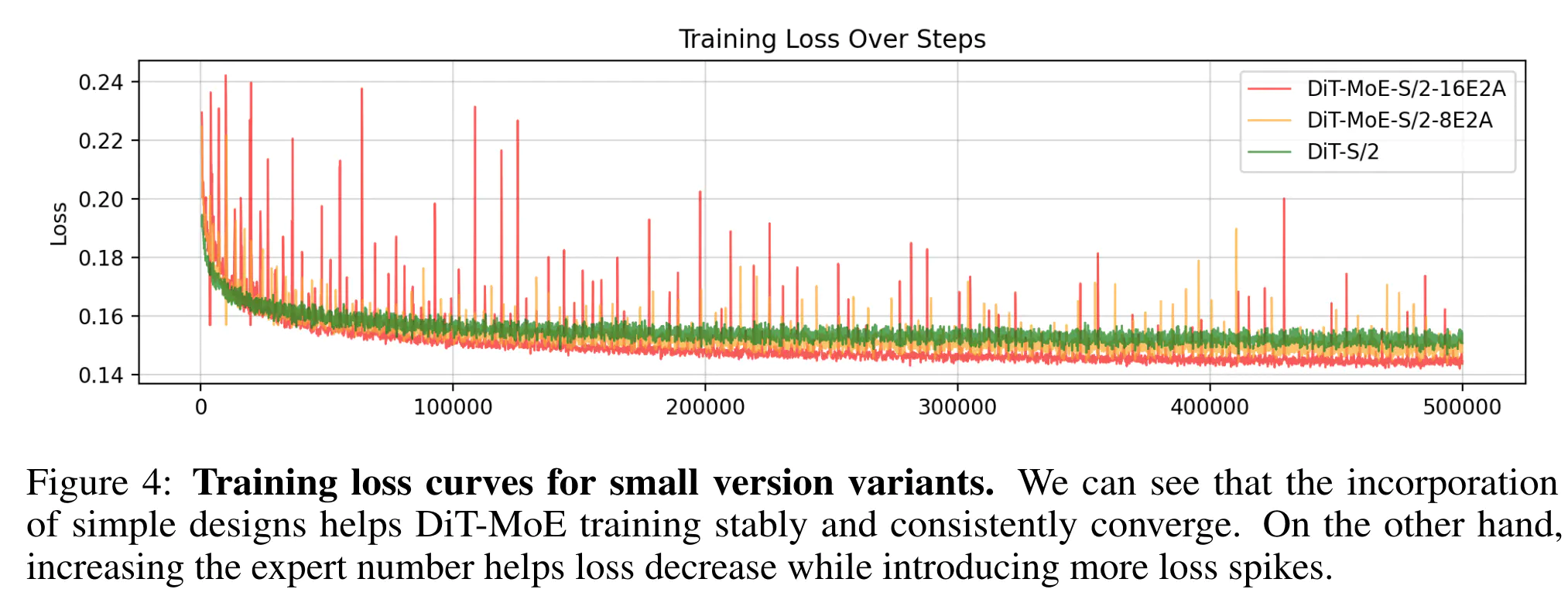
- 我们直接将专家数量从 8 增加到 16,同时保持激活参数的数量固定为 2。如图 3 (b) 所示,此调整带来了持续的生成性能提升,但 GPU 内存消耗显著增加。另一方面,图 4 中的损失曲线显示,引入 MoE 可以实现具有竞争力的性能,并有助于加速损失收敛。然而,直接增加专家数量以提高性能可能会引入更多的损失峰值。如何减少损失峰值,如峰值正则化损失,我们将在未来的工作中探讨。
- 扩展模型规模。
- 我们还通过研究模型深度(即块的数量、隐藏维度和头的数量)的影响来探索 DiT-MoE 的扩展特性。具体来说,我们训练了四种不同配置的 DiT-MoE 模型,涵盖从 Small 到 XL 的配置,如表 1 所示,并分别用 (S, B, L, XL) 表示。如图 3 © 所示,随着深度从 12 增加到 28,性能有所提高。同样,宽度从 384 增加到 1152 也带来了性能提升。总体而言,通过增加模型架构的深度和宽度,在所有配置下,FID 指标在所有训练阶段都显示出了显著的改进。
专家专业化分析
- 我们认为,全面的路由分析可以为设计新算法提供宝贵的见解。
- 首先为每个图像类别采样 50 张图像,使用 250 个 DDPM 步骤,总共生成 50K 个数据点。
- 然后,我们从三个角度计算专家选择的频率:图像类别、空间位置和去噪时间步长。
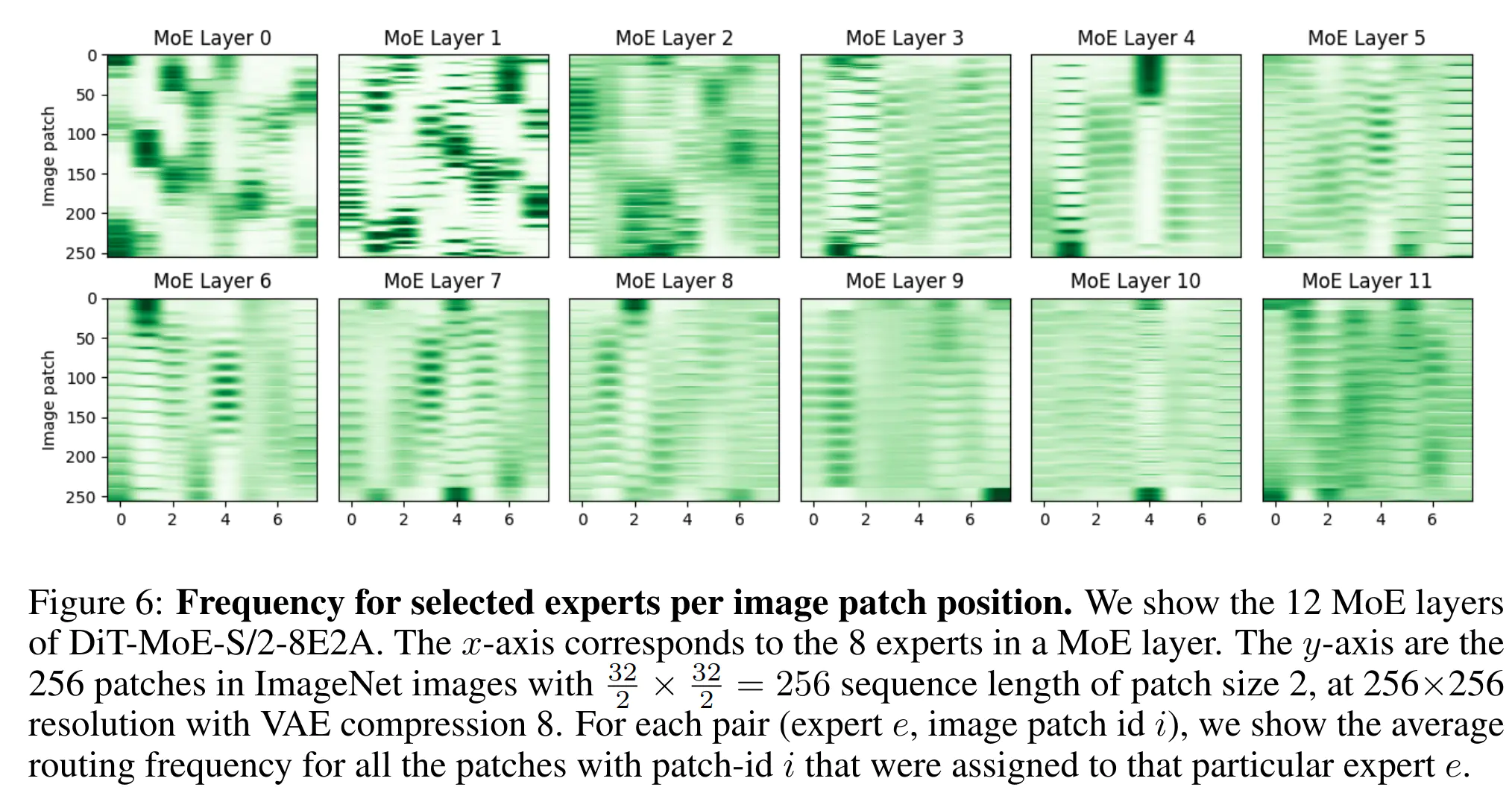
- 可视化热图分别显示在图 5、6 和 7 中。根据我们的观察,几个关键见解浮出水面:
- (i) 通常,学习到的专家路由中没有明显的冗余,不同 MoE 层的每个专家有时都会被路由。
- (ii) 专家选择显示出对空间位置和去噪步骤的偏好,但对类别条件信息不太敏感,这与之前 Practical Plug-And-Play (PPAP) 的假设一致;
- (iii) 如图 5 所示,在不同的类别条件场景下,专家路由机制中没有明显的模式或变化。
- (iv) 随着 MoE 层的加深,专家选择从特定位置偏好过渡到更分散和平衡的分布。例如,在图 6 中,MoE 层 0 的热图表明图像块与空间聚类之间存在强相关性,而 MoE 层 9 的热图显示专家选择分布更加均匀。
- (v) 如图 7 所示,在早期推理步骤(例如,小于 50 的步骤)中,专家选择更为集中,而在后期步骤(例如,大于 100 的步骤)中,分布变得更加均匀。总的来说,这些关于专家路由的发现可以有效地指导未来的结构设计,并增强网络的可解释性。


与 SOTA 模型对比
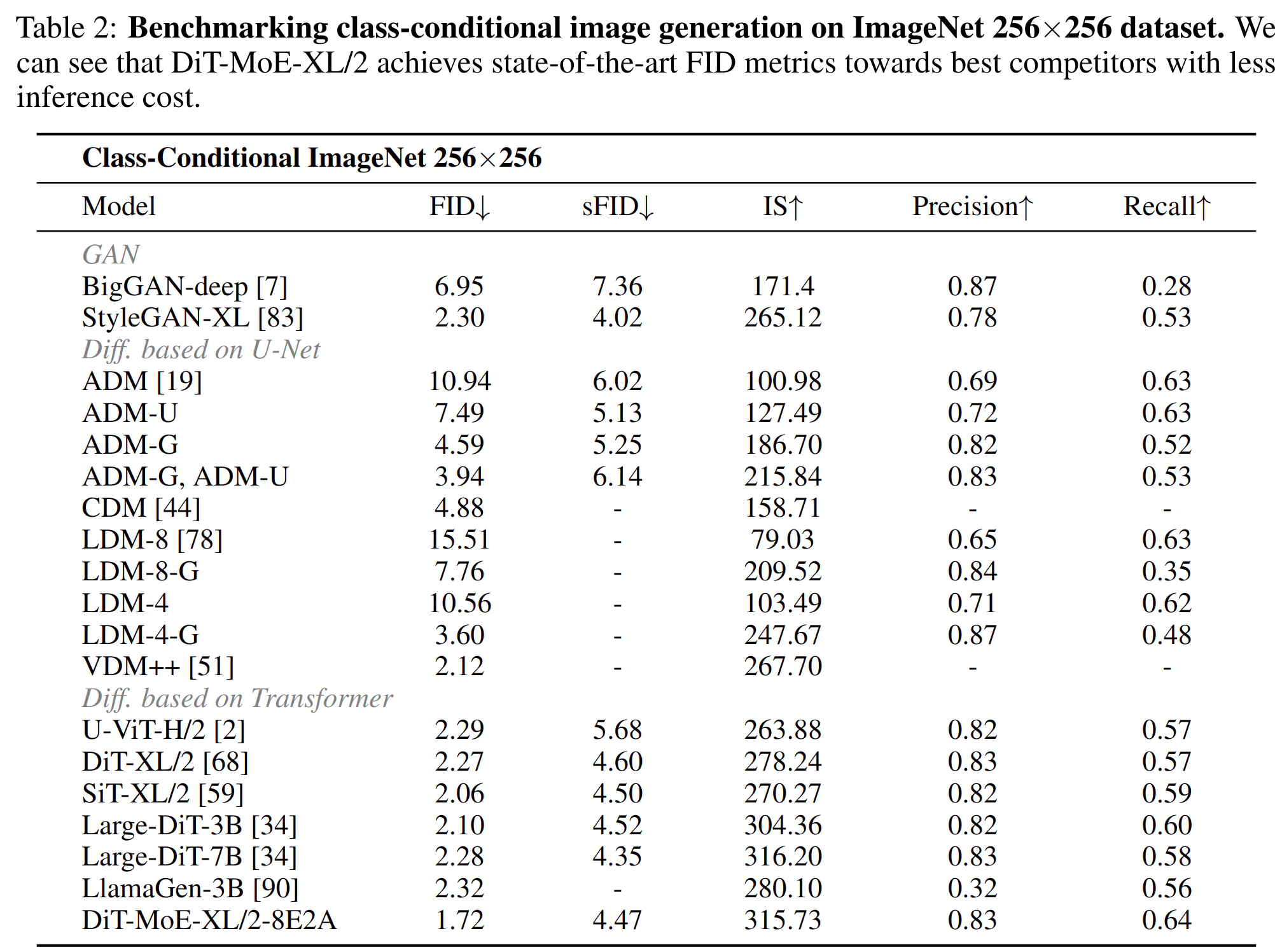
- 在 256×256 分辨率的类别条件 ImageNet 数据集上,我们的 DiTMoE-XL 实现了 1.72 的 FID 分数,超越了所有具有不同架构的先前模型。
Thoughts
- 文章创新点不多,不过实验和分析都比较充分,同时代码开源也是比较良心
- 不同 expert 对于不同 timestamp 比较敏感的分析感觉比较有价值,不同的噪声强度用不同的 expert 来适应是个挺科学的做法。不过从实验的图里来看不同 expert 对于不同 timestamp 的敏感程度似乎还不够大(比如和 image patch 的对比),如果能加些先验强行让不同 expert 关注不同 timestamp 可能也是值得尝试的
文章来源于互联网:Scaling Diffusion Transformers to 16 Billion Parameters
相关推荐: 【Qwen2微调实战】LLaMA-Factory框架对Qwen2-7B模型的微调实践
系列篇章💥 No. 文章 1 【Qwen部署实战】探索Qwen-7B-Chat:阿里云大型语言模型的对话实践 2 【Qwen2部署实战】Qwen2初体验:用Transformers打造智能聊天机器人 3 【Qwen2部署实战】探索Qwen2-7B:通过Fast…












