 5bei.cn大模型教程网
5bei.cn大模型教程网4 Stable Diffusion
Stable Diffusion 是由 Stability AI 开发的开源扩散模型。Stable Diffusion 可以完成多模态任务,包括:文字生成图像(text2img)、图像生成图像(img2img)等。
4.1 Stable Diffusion 的组成部分
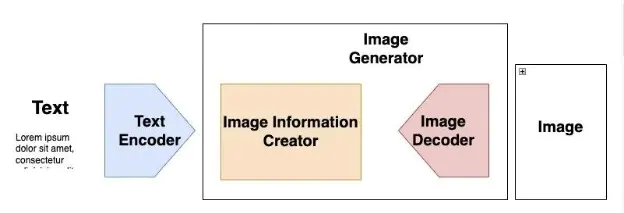
Stable Diffusion 由两部分组成:
-
文本编码器:提取文本 prompt 的信息
-
图像生成器:根据文本 embedding 生成图像
- 图像信息创建器:多步扩散过程。步长是其中一个超参数
- 图像解码器:只在最后生成图像时运行一次
-
**文本编码器:**由一种特殊的 Transformer 编码器组成,例如:OpenAI 的 Clip。
-
图像信息创建器:由自编码器(通常是 U-Net)和噪音机制组成。
-
图像解码器:由自编码器的解码器组成。
Stable Diffusion Pipeline:
-
Clip:文本信息编码
- 输入:文本
- 输出:77 token 的 embedding 向量,每个包含 768 维
-
U-Net + Noise Scheduler:逐渐把信息扩散至潜空间中
- 输入:文本 embedding 和由噪音组成的多维 tensor
- 输出:处
文章来源于互联网:扩散模型 – Stable Diffusion
相关推荐: 图生视频,Stable Diffusion WebUI Forge内置SVD了!
在 Stable Diffusion WebUI Forge 版本中内置了一个SVD插件,也就是 Stable Video Diffusion(稳定视频扩散),之前我介绍过这个工具的使用方法:图片生成视频(独立部署SVD) 但是当时还不能集成到Stable D…













