 5bei.cn大模型教程网
5bei.cn大模型教程网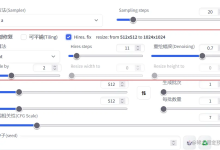
Stable Diffusion支持多人排队使用
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...
如果我们想要自己在云服务器上部署Stable Diffusion模型,但是又不想自动扩容造成成本激增,我们可以设计排队使用的模式。stable-diffusion-webui已经很好用了,支持了自定义模型及Lora模型的加载、排队生成、完善...

系列文章目录 本文专门开一节写SD原理相关的内容,在看之前,可以同步关注:stable diffusion实践操作 前言 (后期补充) 一、原理说明 1.1、出图原理 1.1.1 AI画画不是和人一样,从0开始,而是一个去噪点的过程: 1....

如何在自己的显卡上获得SDXL的最佳质量和性能,以及如何选择适当的优化方法和工具,这一让GenAI用户倍感困惑的问题,业内一直没有一份清晰而详尽的评测报告可供参考。直到全栈开发者Félix San出手。 在本文中,Félix介绍了相关SDX...
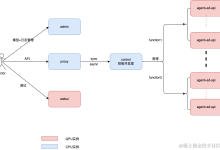
作者:王佳、江昱、筱姜 Stable Diffusion 模型,已经成为 AI 行业从传统深度学习时代走向 AIGC 时代的标志性里程碑。越来越多的开发者借助 stable-diffusion-webui(以下简称 SDWebUI)能力进行...
提前总结 显卡要好,显存要高 素材像素要好,数量越多越好 素材不必要的元素越少越好,太多就扣像留白底 要好好的打标签,影响最终效果 硬件要求 建议N卡且显卡显存至少8G,显存越高越好(即价格越贵越好); 4G需要调整参数,而且速度较慢,不推...

前言 AnimateDiff 是一个实用框架,可以对文本生成图像模型进行动画处理,无需进行特定模型调整,即可为大多数现有的个性化文本转图像模型提供动画化能力。而Animatediff 已更新至 2.0 版本和3.0两个版本,相较于 1.0 ...

目录 背景 最简单用法 进阶用法 高手用法 safetensor 一、概述 二、主要特点 背景 Stable Diffusion 开源后,确实比较火,上次介绍了下 Stable Diffusion 最简单的concept。今天继续介绍下,以...
在启动Stable Diffusion时一直报Torch not compiled with CUDA enabled警告,一开始没在意本着能用就行的态度凑活用,每个图都耗时十多秒,然后本着好奇Torch not compiled with...

一、Debian12安装 教程很多,这儿就不详细说明啦,小编使用的是“debian-12.5.0-amd64-DVD-1.iso”。 二、换源 Debian12需要先换源,才能在安装第三方包时不出现报错 。 1、备份当前镜像源 cp /e...

注:文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。 所谓图片的创成式填充,就是基于原有图片进行扩展或延展,在保证图片合理性的同时实现与原图片的高度契合。是目...




