 5bei.cn大模型教程网
5bei.cn大模型教程网
2025年最新Stable Diffusion下载+安装+使用教程(超详细版本),学不会你找我
注意: 本文讲解的用的是用“整合包”来本地部署安装及使用Stable Diffusion WebUI,你不需要懂太多的计算机知识,而且用整合包对新手也是比较友好的,磁盘需要预留100G~200G空间才能玩。 整合包我会放在文末 前言 本文将...
注意: 本文讲解的用的是用“整合包”来本地部署安装及使用Stable Diffusion WebUI,你不需要懂太多的计算机知识,而且用整合包对新手也是比较友好的,磁盘需要预留100G~200G空间才能玩。 整合包我会放在文末 前言 本文将...

GpuGeek 实操指南:So-VITS-SVC 语音合成与 Stable Diffusion 文生图双模型搭建,融合即梦 AI 的深度实践 前言 本文将详细讲解 So-VITS-SVC 语音合成与 Stable Diffusion 文生图...

领略AIGC领域Midjourney的强大力量 关键词:AIGC、Midjourney、文本生成图像、扩散模型、创意生成、AI艺术、提示词工程 摘要:本文深入探讨AIGC(人工智能生成内容)领域中Midjourney这一革命性工具的强大能力...

目录 一. 技术架构 二. 导入虚拟机 三. 私有大模型 1. 为什么要有私有大模型? 2. 私有大模型解决方案 四.Ollama 入门 1. 什么是Ollama? 2. 下载安装Ollama 3. 运行通义千问大模型 4. 对话指令详...

Diffusion Model、LDM 、DiT 的关系 Diffusion Model(扩散模型)、Latent Diffusion Model(LDM)和Diffusion Transformer(DiT)是生成式AI中紧密关联的三类模...

一. 摘要 Stable Diffusion是一个基于Latent Diffusion Models(LDMs)实现的以文生图(text-to-image generation)模型,能够生成高分辨率图像。它的原理涉及Diffusion M...

前言 ComfyUI 现已支持 Stable Diffusion 3.5 Medium!人人都能轻松上手的图像生成利器 大家翘首以盼的Stable Diffusion 3.5 Medium模型终于来了!就在今天,Stability AI 正...
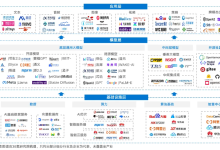
2024年2月,OpenAI发布其首款视频生成模型Sora,用户仅需输入一段文字即可生成长达一分钟场景切换流畅、细节呈现清晰、情感表达准确的高清视频,与一年前的AI生成视频相比,在各维度均实现了质的提升。这一突破再次将AIGC推向大众视野。...

一、概述 本文使用秋叶大佬发布的【绘世整合包】作为软件,它是目前市面上最易于使用的整合包之一,无需对网络和Python有太多的前置知识,已经为AI绘画的普及做出了巨大贡献。绘世启动器整合包于2023年4月16日发布,集成了过去几个月中AI绘...

注意: 本文讲解的用的是用“整合包”来本地部署安装及使用Stable Diffusion WebUI,你不需要懂太多的计算机知识,而且用整合包对新手也是比较友好的,磁盘需要预留100G~200G空间才能玩。 整合包我会放在文末 前言 本文将...


