5bei.cn大模型教程网
5bei.cn大模型教程网
ESP32-S3百度文心一言大模型AI语音聊天助手(支持自定义唤醒词训练)【手把手非常详细】【万字教程】
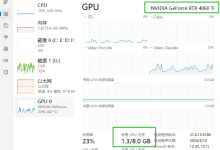
简介 此项目主要使用ESP32-S3实现一个AI语音聊天助手,可以通过该项目熟悉ESP32-S3 arduino的开发,百度语音识别,语音合成API调用,百度文心一言大模型API的调用方法,音频的录制及播放,SD卡的读写,Wifi的配置(s...
简介 此项目主要使用ESP32-S3实现一个AI语音聊天助手,可以通过该项目熟悉ESP32-S3 arduino的开发,百度语音识别,语音合成API调用,百度文心一言大模型API的调用方法,音频的录制及播放,SD卡的读写,Wifi的配置(s...

文章链接:https://arxiv.org/pdf/2403.03206 扩散模型通过反转数据到噪声的正向路径来从噪声中创建数据,并已成为处理高维感知数据(如图像和视频)的强大生成建模技术。Rectified flow是一种最近提出的生成...

导读 基于next-token prediction的图像生成方法首次在ImageNet benchmark超越了LDM, DiT等扩散模型,证明了最原始的自回归模型架构同样可以实现极具竞争力的图像生成性能。 Llama也能做图像生成?文生...

艺术写真,以其独特的魅力,吸引了无数艺术爱好者和摄影爱好者。如今,借助Stable Diffusion的IP-Adapter和InstantID技术,你只需一键操作,就能轻松实现超高相似度的人物换脸写真。本文将带你深入了解Stable Di...

基于diffusers的Stable diffusion训练代码 这里给大家介绍一个基于diffusers库来训练stable diffusion相关模型的训练代码,包含Lora、ControlNet、IP-adapter、Animated...

一、智言川语 这款 AI 绘画软件 Ideogram,我认为是设计师、运营、自媒体从业人员需要重视起来的,如果你不会或者是不了解它,那么这一篇文章你一定要认真研读一下。 为什么我会说这款软件很重要?答案是它在做设计上真的太好用了,一键出海报...

前言 真没想到,距离视频生成上一轮的集中爆发(详见《Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才过去三个月,没想OpenAI一出手,该领域又直接变天了 自打2.16日Op...

引言 在人工智能的辉煌星河中,多模态基础模型犹如一颗颗璀璨的新星,引领着技术发展的新潮流。这些模型通过整合文本、图像、声音等多种数据类型,极大地拓展了机器理解与生成的能力边界。随着技术的不断进步,多模态基础模型正逐渐成为智能系统的核心,它们...

关于 GitHub Copilot 和 JetBrains IDE GitHub Copilot 在编写代码时提供 AI 对程序员的自动完成样式的建议。 有关详细信息,请参阅“关于 GitHub Copilot Individual”。 如...

大家好我是极客菌,前两周Stable Diffusion WebUI1.6.0发布了,新增了很多对SDXL生态的支持。 而ControlNET也对SDXL的支持也逐渐稳定。 SDXL的生态终于有一点起色了,我也觉得是时候,可以来写一篇SDX...