 5bei.cn大模型教程网
5bei.cn大模型教程网
超多案例!让 Lovart 作图更好看更高效的提示词在这里了!
嗨大家好!周末愉快! 相信近期大家已经被 Lovart 的相关讯息刷屏好多次了,我在设计群里也看到了群友们陆陆续续拿到了邀请码。尝试了很多玩法,看得我也觉得真的非常强也很有趣,今天我也使用 Lovart 做了一些尝试,同时有一些使用方法和小...
嗨大家好!周末愉快! 相信近期大家已经被 Lovart 的相关讯息刷屏好多次了,我在设计群里也看到了群友们陆陆续续拿到了邀请码。尝试了很多玩法,看得我也觉得真的非常强也很有趣,今天我也使用 Lovart 做了一些尝试,同时有一些使用方法和小...

AIGC特征识别与去除的研究 摘要:随着人工智能生成内容的普及,如何有效识别并去除其中的特征成为研究热点。本文针对这一问题,提出了一种基于深度学习的AIGC特征识别与去除方法。首先,通过分析AIGC内容的特点,设计了一套特征...

论文名称 什么是对比学习? 既然是对比学习,那我们首先要对对比学习有个概念。 对比学习的数据大部分为两种,一种为正样本对,一种为负样本对。模型需要做的就是分清楚输入的数据是是否为正样本对。 示例: 动物-牛 为正样本对 动物-人 为负样本对...
多模态与 AIGC:用 TensorFlow 构建图文 / 语音 / 视频生成模型 🎯 本章目标 了解主流 AIGC 多模态模型架构(图像、语音、视频) 构建文本生成模型(GPT-like) 构建图文生成模型(图像 Caption / Te...

前言 终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏...

(1)MambaVision(NVIDIA视觉网络) 2025.03.09 混合新架构MambaVision来了!Mamba+Transformer混合架构专门为CV应用设计。MambaVision 在Top-1精度和图像吞吐量方面实现了新...

前言 LLM推理优化系统工程概述 截止到目前市面上比较主流的基于文字生成影像的模型都是基于了3大部分组成的。 Encoder Model , Generation Model ,Decoder Model。并且这三个部分是分开训练,然后组合...

Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer-CVPR...

一、为什么数据集对AIGC如此重要? 1. 数据决定模型的知识边界 AIGC模型依赖于大量数据进行训练,以学习输入与输出之间的复杂映射关系。如果数据覆盖面不足,模型将难以生成多样化、创新性的内容。 2. 数据质量直接影响生成效果 数据噪声、...
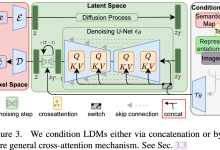
Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解 一、简介 2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffu...




