 5bei.cn大模型教程网
5bei.cn大模型教程网
字节携港大南大升级 LLaVA-NeXT:借 LLaMA-3 和 Qwen-1.5 脱胎换骨,轻松追平 GPT-4V
文 | 王启隆 出品 | 《新程序员》编辑部 2023 年,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员共同开发的 LLaVA 首次亮相,彼时它被视为一个端到端训练的大型多模态模型,展现了在视觉与语言融合领域的潜力。今年 1 ...
文 | 王启隆 出品 | 《新程序员》编辑部 2023 年,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员共同开发的 LLaVA 首次亮相,彼时它被视为一个端到端训练的大型多模态模型,展现了在视觉与语言融合领域的潜力。今年 1 ...

不想用全自动的venv,手动配了一遍 踩过一次坑了,记录一下 https://github.com/AUTOMATIC1111/stable-diffusion-webui 用不用git都无所谓 release或者直接下zip都可 网络不好...

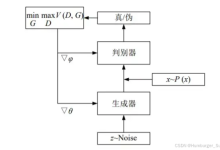
High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022)https://arxiv.org/abs/2112.10752latent-diffusions...

👨背景与来源 最近在stable diffusion的粉丝群看到光影控制又有了新的玩法,是controlnet的作者lllyasviel,发了一款名为IC-Light的模型,并且已经被另外一位名为huchenlei的朋友实现了comfyui...
在Windows下搭建Stable Diffusion环境需要以下几个步骤: 安装Git和Anaconda 首先,确保你的计算机上已经安装了Git和Anaconda。如果没有安装,可以分别访问官方网站进行下载和安装: Git: https:...
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 近段时间AIGC发展非常迅速,尤其在艺术领域的发展全面开花,各位AI绘画师各显身手,百花齐放。小编经过一周多的学习初窥门径,希望把这些工作学习心得记录下来,同各位同行一...

前言: 学习 ComfyUI 是一场持久战,而 ComfyUI layer style 是一组专为图片设计制作且集成了 Photoshop 功能的强大节点。该节点几乎将 PhotoShop 的全部功能迁移到 ComfyUI,诸如提供仿照 A...
💎内容概要 在近期,stable diffusion webui更新了1.9版本,其中包含的一项变化就是,把采样器和调度器(Schedule type)分开了,之前是合并在一起来选择的,所以这篇文章主要分两个部分,第一个部分是作者为什么把他...
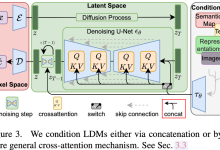
一、简介 2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。 然而,早期的DM直接作用于像素空间,这意味...

这里说LoRA 在 Stable Diffusion 中的三种应用 LoRA 是当今深度学习领域中常见的技术。对于 SD,LoRA 则是能够编辑单幅图片、调整整体画风,或者是通过修改训练目标来实现更强大的功能。LoRA 的原理非常简单,它其...
![[LLM+AIGC] 04.零基础DeepSeek接入WPS实现智能办公-5bei.cn大模型教程网](https://file.5bei.cn/2025/02/frc-f24a2fede8088b282a59f491c1278605-220x150.png)

