 5bei.cn大模型教程网
5bei.cn大模型教程网
Stable Diffusion初步见解(一)
前言 主流AI绘图工具 ——Stable Diffusion(简称SD) 是一种基于扩散模型的图像生成算法。它通过逐步添加噪声并反向扩散来生成高质量的图像。SD在多个领域表现出色,包括图像修复、图像生成和图像增强等。该技术的主要优势在于其...
前言 主流AI绘图工具 ——Stable Diffusion(简称SD) 是一种基于扩散模型的图像生成算法。它通过逐步添加噪声并反向扩散来生成高质量的图像。SD在多个领域表现出色,包括图像修复、图像生成和图像增强等。该技术的主要优势在于其...

项目地址 https://github.com/hiyouga/LLaMA-Factory 模型层参数 这段代码是使用Python的dataclasses模块定义的一个数据类ModelArguments,用于管理和存储与模型微调相关的参数。...

ComfyUI是一个功能丰富、高度可定制的Stable Diffusion操作界面,适合需要精细控制和高度自定义的用户。通过其模块化、低内存需求和快速启动等特点,ComfyUI为图像生成、AI研究、游戏开发等领域提供了强大的支持。 下载(需...
探索音频转文字的高效之道:whisper-rs项目解析与应用 whisper-rsRust bindings to https://github.com/ggerganov/whisper.cpp项目地址:https://gitcode.c...

我们采用 LLaMA-Factory平台进行微调语言模型,详细信息可以访问github主页(https://github.com/hiyouga/LLaMA-Factory)浏览。 租赁显卡 采用AutoDL作为云平台进行微调训练。Win系...
Cog-Stable-Diffusion 开源项目指南 cog-stable-diffusionDiffusers Stable Diffusion as a Cog model项目地址:https://gitcode.com/gh_mir...

大模型场景实战培训,提示词效果调优,大模型应用定制开发,点击咨询 概述 随着人工智能技术的不断进步,越来越多的人开始关注和使用AI艺术生成工具。而Stable Diffusion 3作为最新一代的文生图大模型,于2024年6月12日正式开源...
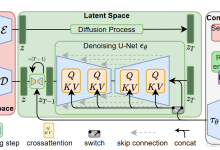
目录 Latent Diffusion Model LDM 主要思想 LDM使用示例 LDM Pipeline LDM 中的 UNET 准备时间步 time steps 预处理阶段 pre-process 下采样过程 down sampl...

SenseVoice是阿里云通义实验室开发的一款多语言音频基础模型,专注于高精度多语言语音识别、情感辨识和音频事件检测。 SenseVoice支持超过50种语言的识别,并且在中文和粤语上的识别效果优于Whisper模型,提升了50%以上。 ...

在 Stable Diffusion WebUI Forge 版本中内置了一个SVD插件,也就是 Stable Video Diffusion(稳定视频扩散),之前我介绍过这个工具的使用方法:图片生成视频(独立部署SVD) 但是当时还不能集...



