 5bei.cn大模型教程网
5bei.cn大模型教程网
AI绘画lora模型篇,stable diffusion 生成模型基础知识,看完就会
最近一直有粉丝在后台留言,说哪怕有完整的提示词信息,也无法对原始图片进行复原。其实如果想复原一张图片,需要用到的参数和注意事项比较多,另外就是即使你的生成参数完全一致,不同的显卡生成的图片也会有些微差别。不过如果你生成的图片差别太大,那肯定...
最近一直有粉丝在后台留言,说哪怕有完整的提示词信息,也无法对原始图片进行复原。其实如果想复原一张图片,需要用到的参数和注意事项比较多,另外就是即使你的生成参数完全一致,不同的显卡生成的图片也会有些微差别。不过如果你生成的图片差别太大,那肯定...

Copilot for Microsoft 365 Plugins 示例项目教程 Copilot-for-M365-Plugins-Samples Microsoft Copilot for Microsoft 365 Plugins sa...

如果只是想体验stable diffusion 绘画功能不必按照本教程安装可以移步下面B站Up主课程安装别人配置好的整合包:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 |...

1. 角色类型六大方向 1.1 Midjourney 角色万能公式 Midjourney 是一种 AI 扩散模型,它通过我们输入的书面提示词,从噪音中创建图像。 Midjourney 在创作人物角色万能公式: 「角色描述」+「视角」+「距离...

LLaMA-Factory 如何高效地微调和部署大型语言模型(LLM)? LLaMA-Factory作为一个开源的微调框架,应运而生,为开发者提供了一个简便、高效的工具,以便在现有的预训练模型基础上,快速适应特定任务需求,提升模型表现。LL...

✨ 1: LLaMA-Omni LLaMA-Omni是基于Llama-3.1-8B-Instruct构建的语音语言模型,支持高质量低延迟的语音互动。 LLaMA-Omni是一个基于Llama-3.1-8B-Instruct构建的语音语言模型...

随着人工智能生成内容(AIGC)技术的飞速发展,我们正处在一个数据爆炸的时代。在这个时代,数据不仅是企业的核心资产,更是推动社会进步和创新的关键力量。然而,如何从海量数据中提取有价值的信息,并以直观、准确的方式呈现,成为了一个亟待解决的问题...

《新手指南:快速上手Trinart Stable Diffusion模型》 trinart_stable_diffusion_v2 项目地址: https://gitcode.com/mirrors/naclbit/trinart_stab...

今天心血来潮想要给vscode配置一个copilot,正好上学期在github上通过教育邮箱实现了学生认证,可以免费使用copilot服务(bushi)。 首先是按照官网(Getting code suggestions in your I...
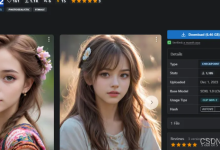
今天和大家分享一个基于SD1.5基础模型训练的人像大模型AWPortrait。该模型在真人写实摄影方面效果超级逼真,能够模拟在真实摄影中的光影效果、皮肤纹理质感、甚至是人物的表情和妆容。 目前最新的版本是V1.4,在V1.3版本的基础上升级...




